Cooking with data
Feb 8, 2024
foto
 Navlepillende navneleg
Feb 7, 2024
hverdag
Navlepillende navneleg
Feb 7, 2024
hverdag
 Navne kan på godt og ondt sende signaler om hvem vi er. Navne og titler kan spille en kolossal rolle for hvordan vi møder et menneske, vælger at
Søgning på steroider
Feb 5, 2024
tech
Navne kan på godt og ondt sende signaler om hvem vi er. Navne og titler kan spille en kolossal rolle for hvordan vi møder et menneske, vælger at
Søgning på steroider
Feb 5, 2024
tech
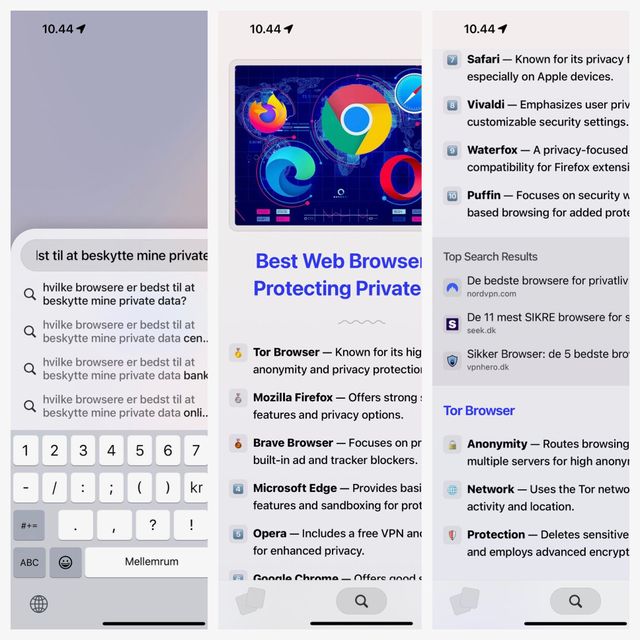 Hvad er en god søgemaskine, og hvilke resultater er vi egentlig på jagt efter, når vi taster ord ind i søgefeltet, uanset om vi så bruger Google,
Komplet irrationelt kamera-begær
Feb 3, 2024
tech
Hvad er en god søgemaskine, og hvilke resultater er vi egentlig på jagt efter, når vi taster ord ind i søgefeltet, uanset om vi så bruger Google,
Komplet irrationelt kamera-begær
Feb 3, 2024
tech
 Jeg bliver nødt til på forhånd at undskylde min totale mangel på viden i det efterfølgende. Så hvis du er fotografsnob og/eller professionel og
Efter gadefesten
Feb 2, 2024
foto
Jeg bliver nødt til på forhånd at undskylde min totale mangel på viden i det efterfølgende. Så hvis du er fotografsnob og/eller professionel og
Efter gadefesten
Feb 2, 2024
foto
 Syv år som selvstændig
Jan 31, 2024
hverdag
Det er næsten ikke til at fatte, men her den 1. februar er det søreme hele 7 år siden jeg sprang ud som selvstændig efter mange, mange år i DR – og
Tirsdags-udsigt
Jan 30, 2024
foto
Syv år som selvstændig
Jan 31, 2024
hverdag
Det er næsten ikke til at fatte, men her den 1. februar er det søreme hele 7 år siden jeg sprang ud som selvstændig efter mange, mange år i DR – og
Tirsdags-udsigt
Jan 30, 2024
foto
 Ny abonnementtracker-app
Jan 28, 2024
hverdag & tech
Ny abonnementtracker-app
Jan 28, 2024
hverdag & tech
 Som bekendt er der de seneste år sket et stort skifte fra engangs-betalinger til abonnementer, ikke mindst når det gælder apps, software og
Skulderklap fra min digitale assistent
Jan 26, 2024
hverdag & tech
Som bekendt er der de seneste år sket et stort skifte fra engangs-betalinger til abonnementer, ikke mindst når det gælder apps, software og
Skulderklap fra min digitale assistent
Jan 26, 2024
hverdag & tech
 Jeg prøvede – med blandede forventninger – at se om Chatty kunne lokkes til at skrive én af mine ugentlige 3 blogsposts, men jeg tror den er blevet
Tillykke med de 40 til Macintosh
Jan 24, 2024
foto
Jeg prøvede – med blandede forventninger – at se om Chatty kunne lokkes til at skrive én af mine ugentlige 3 blogsposts, men jeg tror den er blevet
Tillykke med de 40 til Macintosh
Jan 24, 2024
foto
 Nye tanker om produktivitet og processer
Jan 21, 2024
hverdag
Nye tanker om produktivitet og processer
Jan 21, 2024
hverdag
 På trods af mine mange eksperimenter med kalenderapps, noteværktøjer og andet gøgl, så gør jeg mig ikke i hverdagen voldsomt mange tanker om hvad
100 små ideer
Jan 18, 2024
hverdag
På trods af mine mange eksperimenter med kalenderapps, noteværktøjer og andet gøgl, så gør jeg mig ikke i hverdagen voldsomt mange tanker om hvad
100 små ideer
Jan 18, 2024
hverdag
 Det er ved at være et par uger siden, at jeg faldt over denne fine lille liste med 100 små ideer, der ifølge forfatteren Morgan Housel “…kan hjælpe
Blad i frostvejr
Jan 16, 2024
foto
Det er ved at være et par uger siden, at jeg faldt over denne fine lille liste med 100 små ideer, der ifølge forfatteren Morgan Housel “…kan hjælpe
Blad i frostvejr
Jan 16, 2024
foto
 Promptkursus
Jan 14, 2024
tech
Efter over et år med ChatGPT og diverse andre samtalerobotter i forskellige versioner, fik jeg endelig i juleferien taget mig sammen til at begynde
Harddisk-jubilæum
Jan 9, 2024
hverdag
Promptkursus
Jan 14, 2024
tech
Efter over et år med ChatGPT og diverse andre samtalerobotter i forskellige versioner, fik jeg endelig i juleferien taget mig sammen til at begynde
Harddisk-jubilæum
Jan 9, 2024
hverdag
 I dag er det 30 år siden, at Tore Leifer bød velkommen til det spritnye radioprogram Harddisken på DR P1. Som tiden dog flyver. Jeg tilbragte
14.190 skridt om dagen
Jan 9, 2024
hverdag
I dag er det 30 år siden, at Tore Leifer bød velkommen til det spritnye radioprogram Harddisken på DR P1. Som tiden dog flyver. Jeg tilbragte
14.190 skridt om dagen
Jan 9, 2024
hverdag
 Så kan jeg søreme igen fejre jubilæum for min ubrudte kæde af daglig gang. Idag markerer nemlig det syvende år, hvor jeg HVER ENESTE dag har gået
Christiansborg i tåget morgenlys
Jan 6, 2024
foto
Så kan jeg søreme igen fejre jubilæum for min ubrudte kæde af daglig gang. Idag markerer nemlig det syvende år, hvor jeg HVER ENESTE dag har gået
Christiansborg i tåget morgenlys
Jan 6, 2024
foto
 Årets Tema 2024
Jan 3, 2024
hverdag & projekter
Årets Tema 2024
Jan 3, 2024
hverdag & projekter
 Som jeg skrev forleden er det her ved årsskiftet tid til at vælge Årets Tema, et løst guidende princip som forhåbentlig kan fungere bedre i
Årets tema 2023 – sådan gik det
Dec 31, 2023
hverdag
Som jeg skrev forleden er det her ved årsskiftet tid til at vælge Årets Tema, et løst guidende princip som forhåbentlig kan fungere bedre i
Årets tema 2023 – sådan gik det
Dec 31, 2023
hverdag
 Det er ved at være tid til at vælge dét, vi omhyggeligt ikke kalder et nytårsforsæt, men et ‘tema for det kommende år’. Det er (som jeg skrev i
Floaking
Dec 30, 2023
hverdag
Det er ved at være tid til at vælge dét, vi omhyggeligt ikke kalder et nytårsforsæt, men et ‘tema for det kommende år’. Det er (som jeg skrev i
Floaking
Dec 30, 2023
hverdag
 I ScifiSnak – podcasten som jeg laver med min gode ven Jens – taler vi i den aktuelle episode 111 om China Mievilles fantastiske sprog-rumfabel
Next page
I ScifiSnak – podcasten som jeg laver med min gode ven Jens – taler vi i den aktuelle episode 111 om China Mievilles fantastiske sprog-rumfabel
Next page
 |||
|||